paneldata数据分析 一
2023-03-16 来源:你乐谷
paneldata数据分析 一
本文核心词:面板数据,panel data多罗罗镇楼
又西三百里五十里,曰莱山,其木多檀楮,其鸟多罗罗,是食人。
好看的番剧越来越少了,基番都没有了,都想脱宅了。

好久都没有写专栏了,本来这次的panel分析是打算让一个博后去做的,因为文章我已经写了绝大部分,就想偷个懒,不想跑数据了。没想到只是想蹭文章,不想出力。果然靠山山会倒 靠人人会跑,还是自己靠谱。于是又捡起统计了。
为什么要用面板数据呢?最直接的的原因还不是截面数据备受歧视。。。
一、基础知识
1、面板数据的特征
①面板数据可以理解为时间序列数据 截面数据
②指的是在一段时间内追踪同一组个体的数据(Panel data include N inp>
③如果解释变量(x)包含被解释变量的滞后值(yt-1),则称为“动态面板”(dynamic panel);反之则为静态面板(static panel)
④如果在面板数据中,每个时期的样本个数相同,称为“平衡面板”(balanced panel,Ti=T, for all i);反之,则是“非平衡面板”(unbalanced panel, Ti≠T)。
⑤我们假设,个体随着时间的改变存在自相关,但是个体之间彼此独立,也就是说不存在共线性问题。解释说的话,就是你的工资(变量)和你前期的工资是存在相关的,但是你的工资和其他人的工资是独立的,不存在相关关系。
2、面板数据的种类
短面板:就是时间很短的面板,哈哈哈哈哈哈。面板T比较短,样本n较大。
长面板:T比较大,n比较小。
both:T和n都很大
3、回归元的种类
①可变回归元(Varying regressors)Xit,比如说你每个季度的老婆数。
②不随时间改变的回归元(Time-invariant regressors)Xit=Xi for t,比如说你的性别(女装大佬不除外)
③不随个体性质改变的回归元(Inp>it=Xt for t,比如说当年国家的失业率,对于每个个体而言,那一年国家的失业率是相同的,不会因为你是沙雕你就会和其他人不一样。
4、因变量和回归元的方差
大概见下图,和方差分析差不多,具体翻译查统计学的书,我忘记了。和方差分析特别像,就是把时间看做分组。

计算过程见下(可以忽略,我就做个笔记)
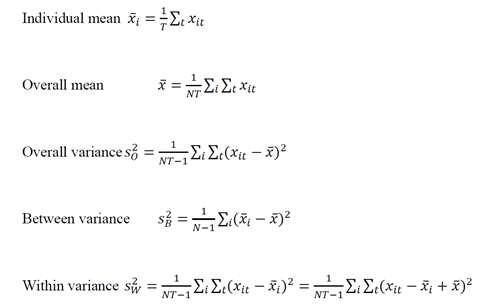
总误差可以分解为组内误差和组间误差

对于不随时间改变的回归元而言,如性别,组内误差为0
对于不随个体性质改变的回归元,如失业率,组间误差为0
attention:We need to check the data to see if the between or within variation is larger for each variable。

二、回归模型
有三种,分别是混合模型、固定效应模型、随机效应模型
1、混合模型(Pooled model)
如果所有个体都拥有完全一样的回归方程,

混合回归模型方程式
这是最简单粗暴的处理方式,把所有的数据混合在一起,当做截面数据去对待,直接跑OLS.
尽管通常我们假设个体之间的扰动项相互独立,但是同一个体不同时间的扰动项存在自相关。这时候,对标准误的估计应该采用聚类稳健的标准误(cluster-robust standard error)。其中聚类(cluster)就是每个个体不同时期的所有观测值组成。同一聚类(个体)的观测值允许存在相关性,不同聚类个体的观测值则不相关。
因此,混合回归也被称为“总体平均估计量”(population-averaged estimator, PA),可以理解为化面板分析为截面分析。
混合回归的基本假设是不存在个体效应,也被认为是最严格的面板数据模型,在文献中不常见。(不常见的意思是不用学了,写paper也发不了)
这一假设的统计检验根据固定效应和随机效应进行检验。
2、个体固定效应模型(Inp>
我们假设给定个体i,个体之间有一些无法观测的异质性变量,用αi描述,比如说你想探索影响一个人升迁的因素,除了学历、专业等等可测变量,还有很多不可测的变量,如“guanxi”和情商等。
那么问题来了,个人的异质性因素αi是否会对回归元造成影响,也就是αi和x是否相关。如果相关,那就是固定效应模型,如果不相关,那就是随机效应模型。(这就是我们检验的依据)
2.1 固定效应模型(Fixed effects model (FE))
固定效应模型允许个体异质效应αi和回归元x相关
我们把αi归纳在截距中
每一个个体都有独自的截距项和相同的斜率
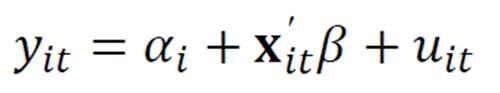
固定效应模型方程式
取估计去掉个体异质效果

换言之,个体异质效应是回归元解释因变量剩下的无法解释的部分。解释不了的东西统统扔进“黑匣子”。
回归元x中可以添加时间虚拟变量
2.2 随机效应模型(Random effects model (RE))
随机效应模型假设个体异质效应αi和回归元x独立(不相关)
我们把αi归纳在误差项中
每个变量都有相同的斜率和合成误差项
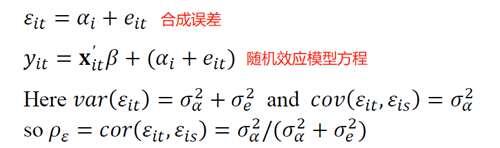
Rho is the interclass correlation of the error. Rho is the fraction of the variance in the error dueto the inp>It approaches 1 if the inp>
idiosyncratic error.
三、面板数据估计
一般而言,面板数据有多种估计方法,估计方法根据组内误差和组间误差不同而选择。但是,总体而言,We prefer estimators that are consistent and efficient. We check for consistency first and then for efficiency。
一致性(Consistency)
当数量足够大的时候,β的估计趋近于β(遵循大数定理)。一句话,样本量越大越好。
有效性(Efficiency)
有效性(最小误差)通常与选择的估计方法有关。比如说当分析的数据满足高斯马尔科夫定理的时候,选择普通OLS就是有效的。
估计方法
混合OLS估计(Pooled OLS estimator)
The pooled OLS estimator is obtained by stacking the data over i and t into one long regression with NT observations and estimating it by OLS
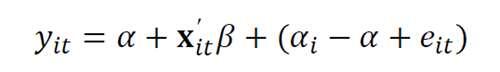
混合OLS估计方程
①如果混合模型( pooled model)是正确的模型,并且回归元和误差项不相关,那么,混合OLS回归则是consistent。
②如果正确的模型是固定效应模型,那么混合OLS回归则是inconsistent。
③我们需要校正面板标准误。
缺点:应用要求比较严格。
组间估计(Between estimator)(应用较少,不用了解)
①The between estimator only uses the between variation (across inp>
②It uses the time averages of all variables。
③This is an OLS estimation of the time-averaged dependent variable on the time-averaged
regressors for each inp>

自变量因变量采取年度均值进行回归
④The number of observations is N. The time variation is not considered and the data are collapsed with one observation per inp>
⑤This estimator is seldom used because the pooled and RE estimators are more efficient。
缺点:低效。
组内估计或固定效应估计(Within estimator or fixed effects estimator)
①The within estimator uses the within variation (over time).
②It uses time-demeaned variables (the inp>
time-averaged values).比如说If an inp>
③This is an OLS estimation of the time-demeaned dependent variable on the time-demeaned regressors.
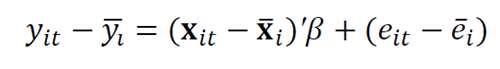
time-demeaned OLS regression

Some software packages estimate
④The number of observations is NT.
⑤The inp>
⑥A limitation of the within estimator is that time-invariant variables are dropped from the model and their coefficients are not identified。
A female/male will have values of 1/0 for the female dummy variable, so the values minus the mean values (calculated over time) for each inp>
If we are interested in the effects of time-invariant variables, we need to consider
different models (OLS or between estimators).
缺点:如果我们要估计不随时间改变的变量,应选择OLS 或者 between estimators。
一阶差分估计(First-differences estimator)
①The first-difference estimator uses the one-period changes for each inp>
②It uses first-differenced variables (the inp>
inp>
③This is an OLS estimation of the one-period changes of the dependent variable on the oneperiod changes in the regressors
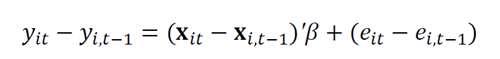
一阶差分后的因变量和一阶差分后的自变量进行OLS回归
④The number of observations is N(T-1). We lose the first observation for each inp>
because of differencing.
⑤和上面的within estimator 一样,The inp>
⑥A limitation of the first-differences model is that time-invariant variables are dropped from the model and their coefficients are not identified
缺点:和上面的within estimator 一样,不能估计不随时间改变的变量,并且不能识别系数。
随机效应估计(Random effects estimator)
①This is an OLS estimation of the transformed model

随机效应模型变换过程
②The number of observations is NT.
③The inp>
④需要注意的是,λ的估计=0 corresponds to pooled OLS and λ的估计=1corresponds to the within (fixed effects)。
⑤The random effects estimates are a weighted average of the between and within estimates。也就是说随机效应估计是between and within estimates的加权平均。
⑥The random effects estimator is fully efficient under the random effects model。
缺点:模型仅适用随机效应模型。
模型和估计汇总
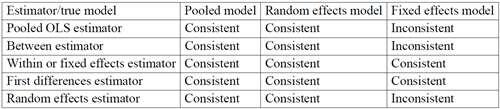
选择适合自己的菜、选择正确的菜
注:
①The fixed effects estimator will always give consistent estimates, but they may not be the most efficient.
②The random effects estimator is inconsistent if the appropriate model is the fixed effects model.
③The random effects estimator is consistent and most efficient if the appropriate model is
random effects model.
模型选择检验(Choosing between fixed and random effects)
1、Breusch-Pagan Lagrange Multiplier test
①This is a test for the random effects model based on the OLS residual。
②确定要求

如果显著,则是用随机效应模型,否则使用OLS
③If the LM test is significant, use the random effects model instead of the OLS model.
④We still need to test for fixed versus random effects.
2、Hausman test
①The random effects estimator is more efficient so we need to use it if the Hausman test supports it. If it does not support it, use the fixed effects model.
②Hausman test tests whether there is a significant difference between the fixed and random
effects estimators.
③The Hausman test statistic can be calculated only for the time-varying regressors.
④The Hausman test statistics is:
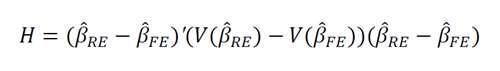
the Hausman test
⑤It is chi-square distributed with degrees of freedom equal to the number of parameters for
the time-varying regressors.
⑥If the Hausman test is insignificant use the random effects.
⑦If the Hausman test is significant use the fixed effects.
参考视频:
多罗罗结尾。



好啦,以上就是paneldata数据分析 一全部内容,都看到这里了还不收藏一下??搜索(面板数据,panel data
)还能找到更多精彩内容。
 主题分类番号库
主题分类番号库










